Text Analyses of Singapore Parliarmentary Debates

tEXT aNALYSIS / nATURAL lANGUAGE pROCESSING
introduction
Parliamentary Questions (PQ) are generally inspired by Singapore residents from which the Member of the Parliaments (MP)s speak to or gathered from their dialogue sessions. Parliamentary Debates are held to debate these questions and often span over two days, amounting to over 100 documents for each sitting. In this project, our group investigated the Parliament Debates to understand the issues and topics that are debated. However, the large volume of documents necessitated the use of text mining techniques and algorithms to comb through all documents.
Hence, our group set out to explore the following three key questions using text mining techniques to comb through the Parliament Debates documents:
- What are the issues concerning Singapore and its people over the last 5 years? – Topic Modelling
- Which are the Ministries & Agencies that are receiving tractions, so for better allocation of resources to address the Singapore Resident’s pressing issues? – Information Extraction
- MP profiling to garner insights of their performance based on their engagements, breadth of domain knowledge and contributions. – Information Extraction
The Dataset
The dataset used for this project is from official reports on parliamentary debates from the official Parliament of Singapore website.
Our group analysed data from the 2015 General Elections (GE2015), to better understand the topics that have been debated over the course at least one election cycle. The first parliament sitting after GE 2015 i.e., 13th parliament was on 15 Jan, 2016. Hence, the time period of analysis will be from 15 Jan, 2016 to 2021 Oct. From this time period, 8410 records in total were extracted.
There were two initial issues when extracting the data from the website:
- There were a total of 8410 records in the selected time period, copying each report manually from the website would take too much time
- The records needed to be cleaned to remove unnecessary information that could interfere with the text analysis process
Our group used the Webdriver function in the Selenium library as well as the BeautifulSoup function in Python to scrape the data from the website instead. This allowed us to create an automated workflow to extract all 8410 records from the website, as each report link was named in numerical order (e.g. https://sprs.parl.gov.sg/search/#/sprs3topic?reportid=oral-answer-2254). Our group extracted the data directly in .txt format and used regex to remove unnecessary information such as Title, Session Number and other Parliarmentary Sitting information.

Exploratory Data Analysis
With the text documents scraped and organized, we performed some exploratory data analysis to get a better understanding of our dataset. We plotted out the most common stopwords, punctuations and words, as this will aid in our preprocessing and cleaning steps later on. The most common words are quite useful, as these are words that are very general (e.g., Singapore, Minister, Speaker, Government) and will not provide useful information for identifying topics. Thus, they need to be removed prior to our topic modelling.


Topic Modelling
The tremendous growth of content on the Internet has inspired the development of text analytics to understand and solve real-life problems. In text analytics, topic models can be used to discover abstract topics that are present in a collection of text documents. There are many topic modelling techniques developed, with one of the most common being Latent Dirichlet Allocation (LDA), which is a fully Bayesian extension of probabilistic latent semantic indexing (pLSI). Ever since, variants of the LDA generative statistical model have been developed for various purposes. In this task, we will be exploring various topic modelling techniques including Gensim LDA Mallet as well as BERTopic.
GENSIM LATENT DIRICHLET ALLOCATION (LDA) mallet
In natural language processing, the LDA model is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. In the case of topic modelling, it “discovers” topics in a collection of documents, then automatically classifies any individual document within the collection in terms of how “relevant” it is to each of the discovered topics.
Machine Learning for Language Toolkit (MALLET) is a Java-based package for statistical natural language processing, document classification, clustering, topic modeling, information extraction, and other machine learning applications to text. It includes sophisticated tools for document classification, sequence tagging and topic modelling. In the case of topic modelling, the MALLET toolkit contains efficient, sampling-based implementations of LDA. Upon further study, it was understood that MALLET uses Gibbs sampling, which is an algorithm for successively sampling conditional distributions of variables, whose distribution over states converges to the true distribution in the long run.
However, there are several assumptions to be made in the LDA model:
- The semantic content of a document is composed by combining one or more terms from one or more topics.
- Certain terms are ambiguous, belonging to more than one topic, with different probability.
- Most documents will contain only a relatively small number of topics. In the collection, e.g., individual topics will occur with differing frequencies. That is, they have a probability distribution, so that a given document is more likely to contain some topics than others.
- Within a topic, certain terms will be used much more frequently than others. In other words, the terms within a topic will also have their own probability distribution.
The exact workflow to run the Gensim LDA model are detailed as follows:
- Document Preprocessing
- Tokenization
- Convert all words to lower-case
- Part-of-speech tagging and lemmatization
- Import stopword list from nltk corpus and remove stopwords
- Gensim to create bigram and trigram models, as well as the corpus and vectors
- Gensim LDA
- Run Gensim LDA via gensim.models by setting an initial number of topics (k)
- Coherence and perplexity score to evaluate the performance of the model
- Optimization
- Optimize topic counts via coherence score
- Iterate through a range of number of topics (k) to find the highest coherence score and hence the optimum number of topics
The initial Gensim LDA model was run by setting the num_topics desired to be 15 as a first guess. The peak coherence score was located at 20 topics, and we re-run the LDA Mallet model which yielded a coherence score of 0.6357. A close second was 23 topics, which yielded a coherence score of 0.6247.

The sample topics are shown below:
Sample topics generated (LDA Mallet)
Topic 1: food, water, waste, NEA, hawker, environment
Topic 2: court, law, case, act, legal, party
Topic 3: act, amendment, ensure, require, company
Topic 4: police, officer, drug, offence, case, home
Topic 5: health, care, healthcare, patient, medical
BERTopic
Although topic models such as Gensim LDA and LDA Mallet have shown to be good starting points, one disadvantage was that it took some effort through hyperparameter tuning to create meaningful topics. Hence, we sought to look at alternative models that could possibly provide more relevant results. Our research chanced upon the Bi-Directional Encoder Representations from Transformers (BERT) model, which is a transformer-based model that had shown amazing results in various NLP tasks over the last few years.
A transformer is a deep learning model that adopts the mechanism of attention, differentially weighting the significance of each part of the input data. It differs from the LDA models used earlier as it uses bi-directional sentence parsing.

The BERTopic model workflow relies on a similar document pre-processing workflow as the previous LDA models. However, it decides on the number of topics generated, and in this case, 100 topics were generated, with a coherence score of 0.6500. Our team also re-run the BERTopic model for 20 topics for comparison with the LDA model. The sample topics are shown below:
Sample topics generated (BERTopic, k = 100)
Topic 1: edition, chapter, repeal, revised
Topic 2: transport, bus, commuters, taxi
Topic 3: token, crypto, scams, license
Topic 4: applicants, ballot, attempts, families
Topic 5: committee, estimates, reserves, parliament
Sample topics generated (BERTopic, k = 20)
Topic 1: health, healthcare, care, patients
Topic 2: employers, workers, employment, manpower
Topic 3: water, smoking, no, nea
Topic 4: we, our, have, are
Topic 5: we, will, mr, are
Topic Modelling Results
From the 2 topic models discussed earlier, an in-depth analysis was conducted using coherence score, perplexity score as well as manual reading of topics generated to determine coherence of topics. All models were optimized (e.g. optimum number of topics).
Perplexity score is an intrinsic evaluation metric that captures how “surprised” a model is of new data it has not seen before and is measured as the normalized log-likelihood of a held-out test set. However, recent studies have shown that perplexity and human judgement are often not correlated, and even sometimes slightly anti-correlated. This limitation of perplexity measure led to the concept of topic coherence to evaluate the coherence between topics inferred by a model. A lower perplexity score (e.g. more negative) would indicate better generalization performance.
This brings us to coherence score, which measures the degree of semantic similarity between high scoring words in the topic. Difference coherence measures are used, but the main one used in this analysis is the C_v measure, which is based on a sliding window, one-set segmentation of the top words and an indirect confirmation measure that used normalized pointwise mutual information (NPMI) and the cosine similarity. Coherence score is measured from 0 to 1, with 1 being most coherent.
Lastly, we recognize that a combination of these two scores still may not be perfectly accurate in analysing the effectiveness of the models. Hence, we also manually read the topics generated in order to determine the best model.
| Model | Coherence Score | Perplexity Score |
| LDA Mallet | 0.6357 | -8.1671 |
| BERTopic (k=100) | 0.6500 | NA |
| BERTopic (k=20) | 0.6579 | NA |
Our team did a manual reading on the topics generated and found that BERTopic had split the topics down into very fine topics on a very specific issue. Additionally, there was the presence of irrelevant topics for topic number of 20. Also, LDA Mallet had generated topics that were more coherent based on human judgement. Hence, we decided to proceed with LDA Mallet model as it gave a relatively high coherence and perplexity score, together with a balanced representation of topics that were not too general or too in-depth.
After completing our analysis of the documents using topic modelling, an output file was generated assigning each document with their dominant topic. The topic terms for each topic were condensed into one word (e.g. covid, measure, pandemic, case, vaccine were condensed as COVID for topic).

Information Extraction
Information extraction involves extracting useful information such as named entities and the relationship between them, from unstructured text data into a structured form that can be easily used for further analyses. The main technique that will be used is Named Entity Recognition (NER). For example, we can find mentions of people asking or answering questions in the report and extract them out. This allow us to leverage our topic modelling to find out the topic that is most related to this person or vice versa. We can also investigate which member is the most active questioner, which can be extended to other entities like ministries.
Named Entity Recognition
To perform NER, we primarily made use of the spaCy module, which is an open-source model that has been trained to perform several NLP tasks, including entity recognition. We also made use of regex to extract out named entities that follow a certain pattern in the text.
Our first task was to extract out ministries that are mentioned in each document. To do this, we first make use of spaCy small (sm) model to perform named entity recognition, and extract out those that are labeled as organizations (ORG). However, this is not a foolproof approach as spaCy makes both false positives (e.g., Antigen Rapid Test) and false negatives (e.g., Multi-Ministry Taskforce). To remove the false positives, we check it against a dictionary filled with known ministries and statutory boards. Statutory boards were also converted to their respective parent ministries using another mapping dictionary.

One of the first questions we asked is what are the topics that various ministries are involved in. This allows us to 1) investigate which topics a certain ministry is working on or concerned with the most as well as other miscellaneous topics that they work on but might not be explicitly known and 2) act as a sanity check to make sure that our named entity extraction is performing well, as we expect to find certain ministries to be more involved in certain topics (e.g., Ministry of Health to be more involved in healthcare topics). To do this, we made use of radar charts, and also made use of the topics generated from the Topic Modelling section in order to visualise this relationship. The y-axis refers to the number of times the respective ministries were mentioned in a document. For example, as expected, the Ministry of Health are most involved in healthcare topics (over 450 documents). Moreover, it is also involved in COVID-related topics, which are lower in numbers since COVID only started in 2020, as well as education and smoking-related topics.

Our second task was to investigate the parliament members who raised the most questions, as well as answered the most questions. A quick intuition would be to have ministers from the multi-ministry taskforce i.e. Minister Gan Kim Yong, Lawrence Wong and Ong Ye Kung answering the most COVID-19 related questions.
In order to determine members who raised questions, we used regex to find and extract the specific pattern inherent in the documents, similar to how ministries were identified (e.g. Mr Chong Kee Hiong asked the Minister for National Development; Mr Leon Perera asked the Minister for Education). The regex will be responsible for retrieving the salutation and full name of the member before the word ‘asked’ in the document. A new ‘asked’ column in the data frame was created to store the names of the members who posed questions to a ministry.

To identify the ministers who answered questions in parliament, we observed that the column ‘mps’ in the data frame contains a list of all parliament members who spoke during the sitting. This may include members who asked and answered questions. Hence, the ministers who answered questions would simply be the delta of the names in ‘mps’ column and names in ‘asked’ column. A screenshot of the code below shows how we sieved the names of those who answered questions, and created a new column called ‘answered’ to store these names:

The interesting part of this task is to analyze which are the most vocal MPs, and the profile of topics raised across the past few years. In order to better visualise this, we made use of Tableau to showcase the Top 20 politicians as well as their count of questions, with color-coding for the party they represent. Unsurprisingly, most of the MPs from the top 20 counts of questions raised, are members from the ruling party, People’s Action Party (PAP). The second most active party would be the Worker’s Party (WP), having 4 members contributing to the top 20 list, as they fulfill their responsibility of introducing more checks and balances in parliament.

Next, we looked at the top 20 ministers who took questions in parliament. As seen from the chart below, majority of the names in the top 20 are from PAP, as questions are mostly directed to the ministers handling the issues.

Zooming into the specific topics, the most active ministers taking questions on COVID, as seen in the chart below, are the current and previous office holders of the Ministry for Health, Mr. Ong Ye Kung and Mr. Gan Kim Yong. Rounding off the top 3 is Mr. Chan Chun Sing, who is the current Minister for Education and would naturally take a large portion of questions pertaining to home-based learning and covid measures in schools.

Finally, we look at the topics most answered by our Prime Minister, Mr. Lee Hsien Loong. His replies are mostly focusing on Infocomm Technology, Housing and Manpower. Usually, the questions will be directed at the ministry responsible for the topic of interest, hence it is interesting to note that PM Lee targets his replies for Infocomm related queries, which are generally regarding digitalization and plans to progress Singapore towards a smart nation.
Key Findings And Results
The key findings and insights from our analysis are dashboard using Tableau. The Tableau Dashboard is found below:
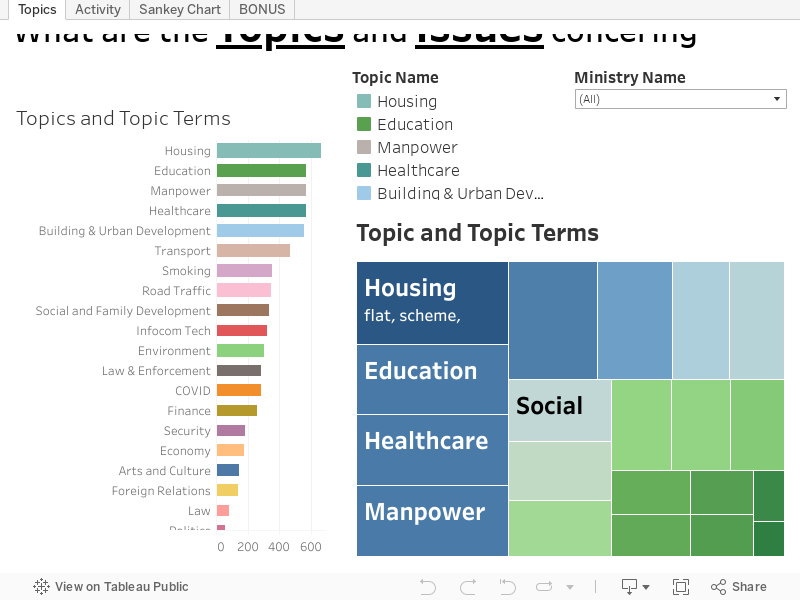
https://public.tableau.com/app/profile/lim.yong.kai/viz/Parliament_Dashboard_FINAL/Topics
Based on the Topics tab, we can see that Housing is the most talked topic over the last 5 years and there is an uptrend for the topic in 2021, despite not having complete data for the year 2021. Education, Manpower, Healthcare and Building & Urban Development are the next few highly debated topics, which is also on an uptrend in 2021. COVID topic has seen a sharp increase in 2020 and 2021, which is expected due to the ongoing conversation over the past 2 years. The filter at the top right corner of the dashboard allows users to filter the Ministries to evaluate what are the topics discussed and growing trend over the years.
From the Activity tab, we can see that there is an uptrend in parliamentary questions asked from the People Action Party (PAP) and Worker Party (WP) in 2021. This shows that there is significant uptrend in activity level in parliamentary debates in the House.
The Sankey chart showcases the questions that each Individual pose to the different ministries. The thickness of each line represents the number of questions the individual asked each ministry. The filter on the top right section allows users to filter the different political party and persons to adjust the input on the left side of the graph by filtering the person name. This dashboard provides insights of the concerns from opposition parties. This will answer our business use case question to understand what the main area of concerns from the opposition parties are. Apart from filtering by political parties, users can also drill down to individuals to compare the distribution of questions asked to each Ministry.
Lastly, the BONUS tab shows the network graph between each Member of Parliarment, as well as their interactions with each other. The line thickness is based on the number of interactions between each person in each parliamentary debate article and we can analyze the relationship between each person. The filtering checkbox at the extreme right will allow users to select the person they are interested to deep dive into.
Future Work and Conclusion
There are several future works that we believed will be important to improving the business use cases:
- The duration of the dataset was in the past 5 years, consisting of the current and previous parliamentary term. While our analysis has yield good insights, we can expand the corpus for a longer period coverage to understand possible recurring issues over the years. For example, is the topic housing always the most popular topic over a longer period? A longer period can also help us understand the shift in position and roles of Ministers. For example, what are the previous roles of our Prime Ministers and determine if we can see a trend prior to when they become the prime minister.
- Topic modeling from LDA Mallet yielded understandable topics for our analysis. Further works to tune the hyperparameters for the model can be explored to generate a more representative sets of topics for Parliamentary debates. We can also explore further into the state-of-the-art transformer BERTopic model, which will require more computational resources and time to train. This can be done using GPUs from paid cloud services like Amazon Web services or free services like Kaggle and Google Colab.
- For NER, we can explore training a NER model or extending the spaCy model with local context training data, which might yield better results and accuracy for entities extraction.
- Visualizations created by Tableau were easy to use, which help illustrate our findings and insights by the entities and topics generated from our Topic Modeling and Information Extraction task. We can explore other text analytic tasks for deeper insights to our data. For example, we can explore relationships between persons using more complex network graph models and visualization techniques. Utilization of open-source software such as Gephi, D3.js or plotly can also potentially provide richer insights, and remove some of the limitations of free accounts in Tableau.
- The data visualization allows users to analyze, dice and slice around the processed modeled topics and the MPs participation/interaction. Future enhancement can include linking this back to the exact document and question for a more drilled down analysis by referencing back to the original PQ. Hence, the ministries would be able to get a quick overview of the insights, funnel down into the details, and going front and back in a systematic and continuous flow to focus on their relevant business use cases.
In conclusion, while there are limitations to our current work and future works to be implemented, we managed to answer the questions that we initially laid out for the project and apply them to our business use case. We believe that the insights we obtain from this project through the use of modern NLP and text analytics approaches, along with the interactive dashboard for impactful visualization, can help different organizations and persons to understand more about the Singapore Parliament Debates, as well as keep abreast of the historical and current trending topics and issues faced by the nation.